DPDPA Penalties Up to ₹250 Crore: The Real Cost of Waiting
July 2, 2026
In the rapidly evolving landscape of data management, organizations are constantly seeking robust architectures to harness the power of their data. Two prominent paradigms have emerged as leading contenders for modern data infrastructure: Data Mesh and Data Lakehouse. While both aim to improve data accessibility, quality, and utility, they approach these goals from fundamentally different perspectives, making the choice between them a critical strategic decision for any enterprise. Understanding their core principles, strengths, and weaknesses is paramount for building a scalable, efficient, and future-proof data ecosystem.
This comprehensive guide will delve deep into the intricacies of Data Mesh and Data Lakehouse, providing a clear comparison of their architectural philosophies, operational models, and ideal use cases. We will explore what each architecture entails, why they are gaining traction in 2024, and the practical steps involved in their implementation. Readers will gain invaluable insights into the prerequisites, best practices, and common challenges associated with each approach, equipping them with the knowledge to make an informed decision tailored to their specific organizational needs and data strategy.
By the end of this article, you will not only have a thorough understanding of Data Mesh and Data Lakehouse but also a practical framework for evaluating which architecture, or perhaps a hybrid approach, is best suited to drive your business forward. We will cover everything from foundational concepts to advanced strategies, ensuring you are well-prepared to navigate the complexities of modern data architecture and leverage your data for competitive advantage. Whether you are a data engineer, architect, business leader, or simply curious about the future of data, this guide offers the clarity and detail needed to master these transformative concepts.
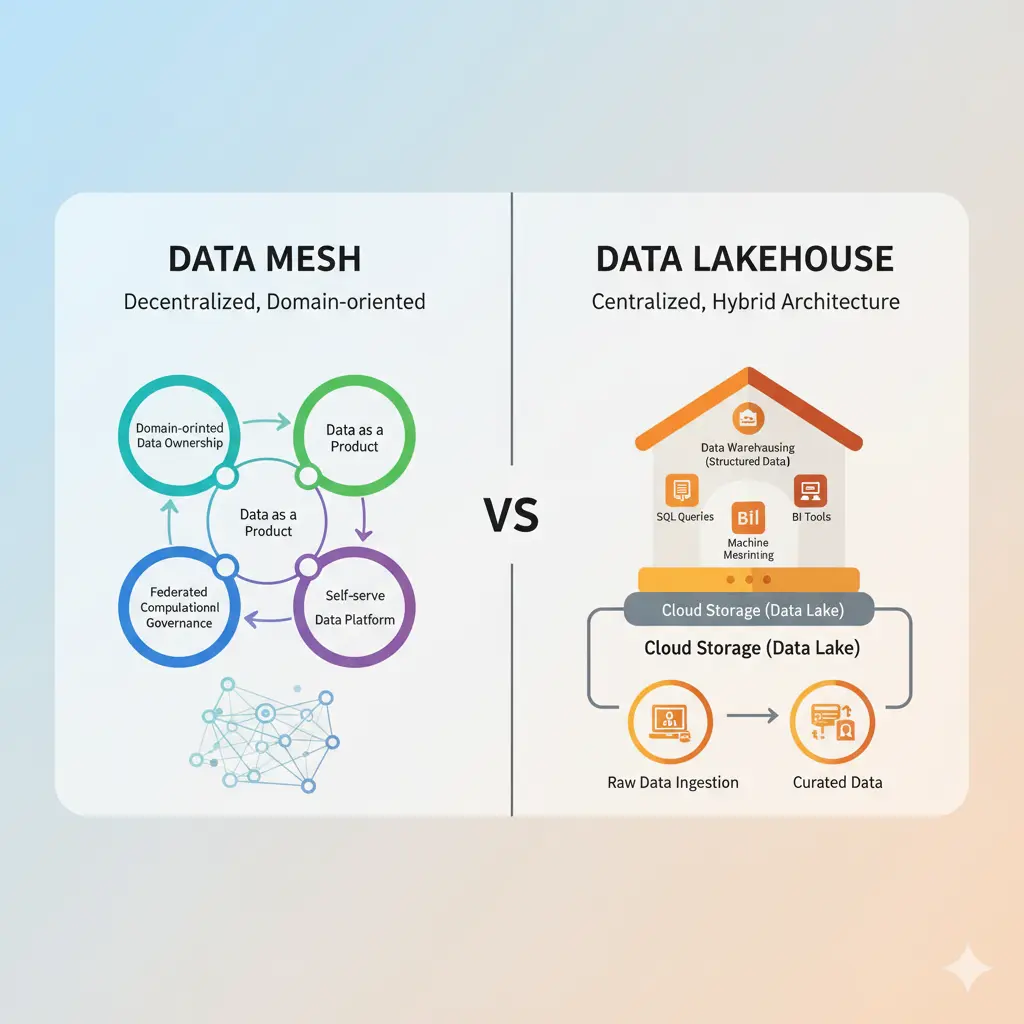
The discussion around Data Mesh versus Data Lakehouse is not merely about choosing between two technologies; it's about selecting a fundamental philosophy for how an organization manages, processes, and derives value from its data. Data Mesh represents a paradigm shift from centralized data ownership to a decentralized, domain-oriented approach, treating data as a product. It advocates for organizational change, empowering individual business domains to own and serve their data, making it readily discoverable, addressable, trustworthy, and self-describing for other domains. This model is particularly suited for large, complex enterprises struggling with data bottlenecks and a single point of failure in a traditional centralized data platform.
In contrast, the Data Lakehouse is an architectural pattern that seeks to combine the best features of data lakes and data warehouses into a single, unified system. It aims to provide the flexibility and cost-effectiveness of a data lake, which can store vast amounts of raw, unstructured, and semi-structured data, with the robust data management features of a data warehouse, such as ACID (Atomicity, Consistency, Isolation, Durability) transactions, schema enforcement, and strong governance. The Data Lakehouse primarily focuses on technical convergence, offering a single platform for diverse workloads including business intelligence (BI), machine learning (and AI), and data warehousing, thereby simplifying the data stack and reducing data movement. It is a technical solution to integrate disparate data processing capabilities.
The choice between these two architectures, or even considering a hybrid model, hinges on an organization's specific challenges, existing infrastructure, cultural readiness for decentralization, and the scale and diversity of its data needs. Data Mesh addresses socio-technical problems related to data ownership and organizational structure, while Data Lakehouse tackles technical challenges related to data unification, performance, and reliability. Understanding these distinct focuses is crucial for making an informed decision that aligns with an organization's strategic objectives and operational realities.
For a Data Mesh, the key components are not primarily technical systems but rather organizational and conceptual pillars. The first is Domain-Oriented Ownership, where cross-functional teams within specific business domains (e.g., sales, marketing, finance) are responsible for their data end-to-end. Second is Data as a Product, meaning data is treated with the same rigor as a software product, with defined consumers, clear APIs, quality standards, and documentation. Third is a Self-Serve Data Platform, which provides the infrastructure, tools, and capabilities for domain teams to build, deploy, and manage their data products independently. Finally, Federated Computational Governance establishes global rules and standards that are enforced locally by domain teams, ensuring interoperability and compliance across the decentralized landscape.
The Data Lakehouse, on the other hand, is defined by its technical components. At its core is a Data Lake Storage Layer, typically object storage like Amazon S3 or Azure Data Lake Storage, which can store all types of data at low cost. Crucially, it incorporates a Metadata Layer (often implemented using open table formats like Delta Lake, Apache Iceberg, or Apache Hudi) that adds transactional capabilities (ACID properties), schema evolution, and indexing to the data stored in the lake. This layer enables data warehouse-like performance and reliability. It also includes Processing Engines (e.g., Apache Spark, Presto, Flink) for various workloads, and BI and ML Tools that can directly query and analyze the data within the Lakehouse, eliminating the need for separate data warehouses or marts.
The core benefits of adopting a Data Mesh architecture are primarily centered around agility, scalability, and data ownership. By decentralizing data responsibility, organizations can break down data silos and accelerate the delivery of data products, as domain teams are empowered to innovate independently without waiting on a central data team. This leads to increased data literacy and accountability across the business. For example, a marketing domain team can quickly build and deploy a customer segmentation data product, iterating rapidly based on business needs, without extensive coordination with a central IT department. This distributed model inherently scales better with organizational growth and increasing data complexity, as new domains can be added without overburdening a single central team.
A Data Lakehouse offers significant technical and operational benefits. Its primary advantage is data unification, providing a single source of truth for all data, whether structured, semi-structured, or unstructured. This eliminates the need for complex ETL pipelines moving data between a data lake and a data warehouse, simplifying the data architecture and reducing operational overhead. For instance, a company can ingest raw clickstream data into the Lakehouse, use it for real-time analytics with BI tools, and simultaneously train machine learning models on the same data without duplication. The Data Lakehouse also offers improved performance and reliability for analytical workloads due to its transactional capabilities and optimized storage formats, while retaining the cost-effectiveness of cloud object storage. It supports a wider range of workloads, from traditional BI to advanced AI, on a single platform.
The relevance of Data Mesh and Data Lakehouse architectures has never been higher than in 2024, driven by an explosion in data volume, velocity, and variety, coupled with an increasing demand for real-time insights and advanced analytics. Organizations are no longer content with slow, batch-oriented data processing; they need immediate, high-quality data to power critical business decisions, personalize customer experiences, and fuel AI/ML initiatives. Traditional monolithic data warehouses and unmanaged data lakes often struggle to meet these modern demands, leading to data silos, governance issues, and slow time-to-insight. Both Data Mesh and Data Lakehouse offer compelling solutions to these challenges, albeit through different lenses, making their consideration crucial for any forward-thinking enterprise.
The shift towards cloud-native architectures and the proliferation of specialized data tools have also amplified the need for more adaptable and scalable data strategies. Companies are looking for ways to democratize data access while maintaining strong governance and security. Data Mesh addresses this by empowering domain teams and fostering a data-driven culture, while Data Lakehouse provides a unified, high-performance technical backbone capable of handling diverse data workloads efficiently. The choice between them often reflects an organization's maturity, its current pain points with data, and its strategic vision for data utilization. Ignoring these modern architectural patterns can lead to competitive disadvantages, as businesses unable to effectively leverage their data will fall behind those that can.
The market impact of Data Mesh and Data Lakehouse architectures is profound, reshaping how businesses approach data strategy and investment. Data Mesh is influencing organizational structures, prompting companies to re-evaluate their data teams and foster greater collaboration between business domains and IT. It's driving the development of new self-serve data platform tools and governance frameworks that support decentralization. For example, large enterprises in retail or finance, with numerous distinct business units, are finding Data Mesh invaluable for breaking down entrenched data silos and accelerating innovation within each unit, leading to faster product development and more targeted customer engagement. This shift is also creating a demand for new skill sets, particularly for data product managers and domain-specific data engineers.
The Data Lakehouse, conversely, is having a significant impact on the technology vendor landscape and the adoption of open-source data formats. It's becoming the de facto standard for many cloud data platforms, with major cloud providers and data companies offering Lakehouse-centric solutions (e.g., Databricks' Delta Lake, Snowflake's hybrid approach, Google Cloud's BigQuery Omni). This architecture simplifies the data stack for many organizations, reducing the need for separate data lakes, data warehouses, and streaming platforms. A mid-sized e-commerce company, for instance, can now use a single Lakehouse platform to ingest real-time order data, perform complex analytical queries for inventory management, and train recommendation engines, all on the same data, leading to substantial cost savings and operational efficiencies. The market is increasingly converging on the Lakehouse model for unified analytics.
Both Data Mesh and Data Lakehouse are poised to remain highly relevant in the future, adapting to emerging trends like real-time data processing, advanced AI/ML integration, and heightened data privacy regulations. Data Mesh's emphasis on data as a product and domain ownership aligns perfectly with the future need for hyper-personalized data experiences and the rapid deployment of AI models that require specific, high-quality data sets. As AI becomes more pervasive, the ability for domain experts to quickly curate and expose their data as reliable products will be critical. For example, in healthcare, a specific research domain can create a data product of anonymized patient records for a particular disease, which can then be easily consumed by AI models developed by another research team, accelerating drug discovery.
The Data Lakehouse will continue to evolve as the foundational technical architecture for unified data platforms. Its ability to handle diverse data types and workloads, combined with ongoing advancements in open table formats and query engines, ensures its longevity. Future developments will likely focus on even tighter integration with real-time streaming capabilities, enhanced governance features, and more sophisticated data cataloging and discovery tools, further blurring the lines between operational and analytical systems. As organizations increasingly rely on operational analytics and embedded AI, the Data Lakehouse will serve as the backbone, providing the necessary performance, scalability, and reliability. For instance, autonomous vehicle companies will rely on Lakehouse architectures to store vast amounts of sensor data, process it for real-time decision-making, and train complex AI models for navigation and safety, all within a single, consistent environment.
Getting started with either Data Mesh or Data Lakehouse requires a clear understanding of your organization's current data maturity, strategic goals, and existing technical landscape. For Data Mesh, the initial steps are less about technology and more about organizational readiness and cultural change. It begins with identifying key business domains and empowering them with the autonomy and resources to manage their data. This often involves a pilot project within a single domain to demonstrate the "data as a product" concept, focusing on a high-value data set that can be transformed into a consumable data product. For example, a customer support domain might create a "customer interaction history" data product, making it easily accessible and understandable for the sales team, demonstrating the immediate value of decentralized ownership and clear data contracts.
Implementing a Data Lakehouse, conversely, typically starts with a technical assessment of existing data infrastructure and a strategic plan for migrating data. This involves selecting an appropriate cloud provider and open table format (e.g., Delta Lake, Iceberg, Hudi) that aligns with your technical stack and future needs. The first practical step often involves setting up the core storage layer in a cloud object storage service and then integrating a processing engine like Apache Spark. A common initial project might be to consolidate disparate data sources, such as operational databases, log files, and CSV files, into the Lakehouse, applying schema-on-read or schema-on-write principles to structure the data for analytical queries. The goal is to establish a unified data platform that can serve both traditional BI and emerging machine learning workloads, proving its capability with a tangible use case.
Before embarking on a Data Mesh journey, several prerequisites are essential. First, a strong organizational commitment to decentralization is paramount, as this architecture demands significant cultural and structural shifts. Second, you need identified business domains that are willing and able to take ownership of their data. Third, a foundational understanding of data product thinking is crucial, where data is viewed as a service with clear interfaces and quality guarantees. Finally, a basic self-serve data platform capability or a plan to build one is necessary, providing the tools and infrastructure for domain teams to operate independently. Without these, a Data Mesh implementation can quickly devolve into unmanaged data silos.
For a Data Lakehouse implementation, the prerequisites are more technical. You will need a cloud infrastructure provider (AWS, Azure, GCP) and familiarity with their object storage services. A working knowledge of distributed processing frameworks like Apache Spark is highly beneficial, as it's often central to Lakehouse operations. Understanding data warehousing concepts (schemas, ETL/ELT, ACID transactions) is also important, as the Lakehouse aims to replicate these features. Lastly, a clear data governance strategy is needed to manage data quality, security, and access within the unified platform, ensuring that the flexibility of the data lake doesn't lead to a "data swamp."
Implementing a Data Mesh involves a multi-faceted approach.
A typical Data Lakehouse implementation follows these steps:
Regardless of whether an organization leans towards Data Mesh or Data Lakehouse, or a combination, adhering to best practices is crucial for successful implementation and long-term value. For Data Mesh, a key best practice is to foster a strong data product mindset throughout the organization. This means treating data not just as raw bits, but as a valuable asset with a lifecycle, clear ownership, and defined consumers. For example, a customer data product should have clear documentation, SLAs for data freshness, and an easily discoverable API, just like a software product. Another critical practice is to invest heavily in developer experience for the self-serve platform, ensuring that domain teams can easily create, deploy, and manage their data products without extensive specialized knowledge. This includes providing robust automation, templates, and clear guidelines.
For Data Lakehouse, a fundamental best practice is to prioritize data quality and governance from the outset. While the Lakehouse offers flexibility, it's essential to implement strong schema enforcement, data validation rules, and access controls to prevent the data lake from becoming a "data swamp." For instance, before ingesting customer order data, ensure that product IDs are validated against a master product catalog and that pricing information adheres to specific formats. Another best practice is to optimize data storage and query performance by choosing appropriate file formats (e.g., Parquet, ORC), partitioning strategies, and indexing techniques. Regularly compacting small files and optimizing table layouts can significantly improve query speeds for analytical workloads, ensuring that the Lakehouse delivers on its promise of high performance.
In the realm of Data Mesh, industry standards are still evolving, but several key principles are widely accepted. The concept of FAIR data principles (Findable, Accessible, Interoperable, Reusable) strongly aligns with the "data as a product" philosophy, guiding how data products should be designed and exposed. For instance, making data products discoverable often involves robust data cataloging tools that adhere to open metadata standards. Open APIs and data contracts are also becoming standard for exposing data products, ensuring interoperability between different domains. Tools and frameworks that support declarative infrastructure as code are crucial for building the self-serve data platform, allowing domain teams to provision and manage their data product infrastructure consistently.
For Data Lakehouse, industry standards are more technically defined. Open table formats like Delta Lake, Apache Iceberg, and Apache Hudi are rapidly becoming the de facto standards for bringing ACID transactions and schema capabilities to data lakes. These formats provide a standardized way to manage data versioning, time travel, and concurrent writes, which are critical for reliability. Apache Spark is an industry standard for distributed data processing within a Lakehouse, offering robust capabilities for ETL, streaming, and machine learning. Furthermore, adherence to SQL standards for querying and data manipulation is essential, as it allows a wide range of BI and analytical tools to connect seamlessly to the Lakehouse. Cloud-native services that integrate with these open standards are also becoming the norm, providing scalable and managed solutions.
Experts in Data Mesh recommend starting small and focusing on cultural transformation over immediate technological overhaul. Zhamak Dehghani, the originator of Data Mesh, emphasizes that it's a socio-technical paradigm. Begin with a single, enthusiastic domain team and a well-defined data product to prove the concept and build internal champions. It's also advised to invest in upskilling existing teams in data product management, distributed systems, and modern data engineering practices, rather than solely relying on external hires. Furthermore, experts suggest building a minimal viable self-serve data platform initially, focusing on core capabilities like data ingestion, storage, and basic governance, and then incrementally adding features based on domain team feedback. Avoid trying to build a perfect platform from day one.
For Data Lakehouse, expert recommendations often center on choosing the right open table format based on specific use cases (e.g., Delta Lake for strong ACID and streaming, Iceberg for multi-engine compatibility, Hudi for incremental data processing). It's crucial to design a layered architecture within the Lakehouse, typically with raw, silver (cleaned and conformed), and gold (aggregated for specific use cases) layers, to ensure data quality and reusability. Experts also advise leveraging cloud-native services for managed compute and storage to reduce operational burden and ensure scalability. For example, using managed Spark services or serverless query engines can significantly simplify Lakehouse operations. Finally, prioritize data security and compliance by implementing robust access controls, encryption, and auditing mechanisms from the very beginning, as the Lakehouse often contains sensitive data from across the organization.
Implementing either Data Mesh or Data Lakehouse is not without its challenges, and understanding these common pitfalls is key to successful adoption. For Data Mesh, one of the most frequent issues is organizational resistance to change. Shifting from a centralized data team to decentralized domain ownership requires a significant cultural transformation, and existing teams may resist giving up control or taking on new responsibilities. Another common problem is the complexity of building and maintaining a self-serve data platform. Providing robust, easy-to-use tools and infrastructure for diverse domain teams is a monumental engineering effort, and without it, the Data Mesh can fail to deliver on its promise of autonomy. Furthermore, ensuring consistent data quality and interoperability across independently developed data products can be difficult without strong federated governance and clear data contracts.
The Data Lakehouse also presents its own set of typical problems. A primary challenge is data governance and quality management. While the Lakehouse aims to bring structure to the data lake, without diligent effort, it can still become a "data swamp" if data is ingested without proper schema enforcement, validation, and metadata management. Another frequent issue is performance optimization for diverse workloads. While a Lakehouse can handle both BI and ML, optimizing for both simultaneously can be complex, requiring careful consideration of data partitioning, indexing, and query engine configuration. For example, a query optimized for batch analytics might not perform well for real-time dashboards. Lastly, managing the evolving open-source ecosystem around Lakehouse technologies (e.g., new table formats, Spark versions) can be challenging, requiring continuous monitoring and updates to maintain stability and leverage new features.
For Data Mesh, the most frequent issues include:
For Data Lakehouse, the most frequent issues are:
The root causes of Data Mesh problems often stem from a lack of clear communication and change management. Cultural inertia is typically rooted in fear of the unknown, perceived loss of control by central teams, or a lack of understanding of the benefits of decentralization. Platform overload often arises from underestimating the engineering effort required for a truly self-serve platform or failing to prioritize user experience. Data product definition issues can be traced back to insufficient training in product thinking or a lack of standardized templates and guidelines. Governance gaps occur when the balance between global standards and local autonomy is not properly struck, or when the federated governance model is not clearly communicated and enforced. Skill gaps are a natural consequence of introducing a new paradigm without adequate investment in training and upskilling.
For Data Lakehouse challenges, the root causes are often technical or process-related. Data quality degradation frequently results from a "dump and store" mentality without proper data validation at ingestion or a lack of clear data ownership. Performance bottlenecks are usually caused by poor data modeling, inefficient file formats, or inadequate partitioning strategies that don't align with query patterns. Schema evolution challenges arise when changes are made without proper versioning, backward compatibility planning, or automated schema migration tools. Cost management issues often stem from a lack of monitoring, inefficient resource allocation, or not leveraging cost-optimization features of cloud providers. Tooling fragmentation is a result of an immature ecosystem or a failure to standardize on a core set of interoperable tools and open formats.
Addressing the challenges of Data Mesh and Data Lakehouse requires a combination of strategic planning, technological solutions, and continuous improvement. For Data Mesh, overcoming organizational resistance starts with a strong change management program that clearly communicates the vision, benefits, and new roles. This includes executive sponsorship, workshops, and success stories from pilot projects. To tackle the complexity of the self-serve platform, adopt an iterative, agile development approach, focusing on delivering minimum viable capabilities first and then expanding based on user feedback. For ensuring data quality and interoperability, establish a strong federated governance body with clear guidelines, data contracts, and automated validation tools, empowering domain teams while providing central oversight.
For Data Lakehouse, solving data quality issues requires implementing robust data validation and quality checks at every stage of the data pipeline, from ingestion to transformation. This can involve using data profiling tools, setting up automated alerts for anomalies, and defining clear data ownership for each dataset. To address performance bottlenecks, conduct regular performance tuning by analyzing query logs, optimizing data layouts (e.g., using Z-ordering for Delta Lake), and leveraging caching mechanisms. For schema evolution, utilize the capabilities of open table formats that support schema evolution features and implement a disciplined process for managing schema changes, including backward compatibility testing. By proactively addressing these issues, organizations can unlock the full potential of their chosen data architecture.
For Data Mesh, quick fixes include:
For Data Lakehouse, quick fixes include:
Long-term solutions for Data Mesh involve a sustained commitment to organizational restructuring and skill development. This means investing in continuous training for data product owners, data engineers, and data consumers across all domains. Building a mature self-serve data platform requires a dedicated platform engineering team that continuously develops and refines tools for data ingestion, processing, storage, and governance, ensuring it remains scalable and user-friendly. Establishing a data governance council with representatives from all domains and central IT can ensure that federated governance evolves effectively, adapting to new challenges and technologies while maintaining consistency and compliance across the mesh.
For Data Lakehouse, long-term solutions focus on building a robust and automated data pipeline and governance framework. This includes implementing a comprehensive data observability strategy to monitor data quality, lineage, and performance across the entire Lakehouse. Developing automated schema evolution management processes, potentially using tools that integrate with your chosen open table format, is crucial for handling changes gracefully. For cost optimization, implement intelligent data tiering (e.g., moving older data to cheaper storage tiers) and auto-scaling compute resources that dynamically adjust to workload demands. Finally, fostering a data-centric culture that values data quality and proper data management practices is essential for the sustained success of a Data Lakehouse, preventing it from becoming a neglected data repository.
At an expert level, choosing between and implementing Data Mesh and Data Lakehouse involves sophisticated techniques that push the boundaries of data architecture. For Data Mesh, advanced strategies include the development of polyglot persistence data products, where domain teams choose the best storage technology for their specific data product (e.g., a graph database for social connections, a time-series database for IoT data), all exposed through standardized APIs. This moves beyond a single, monolithic data store. Another expert technique is implementing event-driven data products, where data changes are published as events, allowing consumers to react in real-time. For example, a "customer profile update" event can trigger immediate actions in marketing automation or fraud detection systems, enabling highly responsive business processes.
For Data Lakehouse, advanced techniques often revolve around maximizing performance, scalability, and real-time capabilities. This includes leveraging data virtualization layers on top of the Lakehouse to provide unified views of data without physical movement, especially useful for integrating with external data sources or legacy systems. Implementing materialized views and aggregate tables within the Lakehouse, automatically updated via continuous processing, can significantly accelerate complex analytical queries for BI dashboards. Furthermore, integrating real-time streaming ingestion and processing directly into the Lakehouse, using technologies like Apache Kafka and Flink alongside open table formats, allows for near real-time analytics and operational intelligence, blurring the line between batch and stream processing.
Advanced methodologies for Data Mesh often involve adopting a "platform as a product" mindset for the self-serve data platform itself. This means the platform team treats its internal users (the domain teams) as customers, continuously gathering feedback, prioritizing features, and delivering a highly polished, user-friendly experience. This ensures the platform truly enables autonomy rather than becoming another bottleneck. Another methodology is the implementation of data contracts as code, where the schema, quality expectations, and access patterns of data products are defined in machine-readable formats and enforced automatically through CI/CD pipelines. This ensures strict adherence to data product standards and reduces manual governance overhead.
In the Data Lakehouse context, advanced methodologies include data vault modeling for structuring raw and historical data, which provides flexibility and auditability, especially in complex enterprise environments. Another is the adoption of DataOps principles across the entire Lakehouse lifecycle, automating data pipelines, testing, and deployment to ensure high data quality, faster delivery, and continuous integration. This includes automated testing of data transformations, schema changes, and performance benchmarks. Furthermore, advanced Lakehouse deployments often utilize multi-cloud or hybrid-cloud strategies, leveraging the Lakehouse's open formats to avoid vendor lock-in and optimize for cost or specific regional requirements, allowing data to reside where it makes the most sense.
Optimization strategies for Data Mesh focus on streamlining the creation and consumption of data products. This includes automating data product lifecycle management, from provisioning infrastructure to deploying and monitoring data products, reducing the manual effort for domain teams. Implementing advanced metadata management and data cataloging with AI-driven recommendations can significantly improve data product discoverability and understanding. For example, an AI system could suggest relevant data products based on a user's query history or role. Additionally, optimizing the federated governance framework by leveraging policy-as-code tools and automated compliance checks can ensure that global rules are enforced efficiently without hindering domain autonomy.
For Data Lakehouse, optimization strategies aim for peak performance and cost efficiency. This involves fine-tuning compute resources by selecting the right instance types and scaling policies for different workloads (e.g., using GPU instances for ML training, memory-optimized instances for complex joins). Implementing advanced indexing techniques (e.g., bloom filters, secondary indexes) on frequently filtered columns can dramatically speed up query execution. Data lifecycle management within the Lakehouse, automatically moving older, less frequently accessed data to colder, cheaper storage tiers, is crucial for cost optimization. Furthermore, leveraging data skipping techniques and columnar storage formats (like Parquet or ORC) with optimal compression ratios ensures that queries only read the necessary data, minimizing I/O and improving performance across the board.
The future of data architecture will likely see a continued evolution and potential convergence of concepts from both Data Mesh and Data Lakehouse, driven by the relentless demand for real-time, intelligent, and highly governed data. The increasing complexity of data ecosystems and the need for greater agility will ensure that both paradigms remain relevant, adapting to new technological advancements and business requirements. Organizations will increasingly seek solutions that offer the best of both worlds: the decentralized ownership and product thinking of Data Mesh combined with the unified, high-performance technical backbone of a Data Lakehouse. This hybrid future will focus on seamless integration and interoperability.
One key trend will be the deeper integration of AI and machine learning capabilities directly into the data architectures themselves. This means not just using data for AI, but using AI to manage and optimize data. For example, AI-powered data catalogs will automatically discover and classify data products in a Data Mesh, while AI-driven query optimizers will intelligently manage resources within a Data Lakehouse. The emphasis on data privacy and ethical AI will also drive advancements in federated learning and privacy-preserving analytics, which align well with the decentralized nature of Data Mesh and the unified data processing capabilities of a Lakehouse.
Several emerging trends will shape the future of Data Mesh and Data Lakehouse. One significant trend is the rise of semantic layers and knowledge graphs on top of these architectures. These layers will provide a unified, business-friendly view of data, abstracting away underlying technical complexities and making data products or Lakehouse tables more easily understandable and consumable by a wider audience. Another trend is the increased adoption of data streaming and real-time processing as a first-class citizen in both architectures. This means moving beyond batch processing to enable immediate insights and operational decisions, with open table formats evolving to better support continuous data ingestion and low-latency queries.
Furthermore, we will see greater emphasis on data observability and data contracts. As data ecosystems grow, understanding data lineage, quality, and usage becomes paramount. Automated tools that monitor data health, enforce data contracts, and provide proactive alerts will become standard. The concept of data sovereignty and multi-cloud data governance will also gain prominence, as organizations operate across multiple cloud providers and geographical regions, requiring robust frameworks to manage data residency and compliance. Finally, the evolution of serverless data platforms will continue to simplify the operational burden of both Data Mesh and Data Lakehouse, allowing organizations to focus more on data value creation rather than infrastructure management.
To prepare for the future of data architecture, organizations should adopt a flexible and adaptable mindset, embracing continuous learning and experimentation. For Data Mesh, this means investing in upskilling data teams in areas like data product management, distributed systems, and modern governance frameworks. It also involves building a modular and extensible self-serve data platform that can easily integrate new technologies and adapt to evolving standards. Organizations should start experimenting with data contracts as code and exploring event-driven architectures to lay the groundwork for real-time data products.
For Data Lakehouse, preparing for the future involves standardizing on open data formats and open-source technologies to ensure long-term flexibility and avoid vendor lock-in. Continuously evaluating and integrating new advancements in query engines, storage optimization, and real-time processing capabilities will be crucial. Organizations should also focus on building a robust data governance and observability framework that can scale with increasing data volumes and complexity, leveraging AI-powered tools for automation. Finally, considering a hybrid approach that combines the strengths of Data Mesh (decentralized ownership, data as a product) with the technical efficiencies of a Data Lakehouse (unified storage, transactional capabilities) might be the most pragmatic path forward for many large enterprises, creating a truly resilient and future-proof data ecosystem.
Explore these related topics to deepen your understanding:
The journey to a modern data architecture is complex, with Data Mesh and Data Lakehouse standing out as two powerful, yet distinct, paradigms. Data Mesh champions a decentralized, domain-oriented approach, treating data as a product and fostering organizational agility and ownership. It's a socio-technical transformation ideal for large enterprises grappling with data silos and a need for distributed innovation. In contrast, the Data Lakehouse offers a technical convergence, unifying the flexibility of data lakes with the reliability of data warehouses, providing a single, high-performance platform for diverse analytical and machine learning workloads. The choice between them is not a simple either/or, but rather a strategic decision based on an organization's specific challenges, cultural readiness, and technical capabilities.
Ultimately, the most effective data strategy in 2024 and beyond may not be to exclusively choose one over the other, but to understand how their principles can complement each other. A Data Lakehouse can serve as a robust, unified technical foundation, providing the self-serve infrastructure and reliable data storage that domain teams in a Data Mesh can leverage to build and expose their data products. Conversely, the product thinking and decentralized governance of a Data Mesh can bring much-needed structure and accountability to a Data Lakehouse, preventing it from becoming an unmanaged data swamp. By focusing on data quality, governance, and fostering a data-driven culture, organizations can harness the strengths of both architectures to create a scalable, agile, and intelligent data ecosystem.
To embark on this transformative journey, start by assessing your current data landscape, identifying your most pressing data challenges, and evaluating your organizational readiness for change. Whether you opt for a full Data Mesh, a comprehensive Data Lakehouse, or a hybrid model, prioritize incremental implementation, continuous learning, and a strong commitment to data quality and governance. The future of business intelligence and AI hinges on effective data management, and by making an informed architectural choice, you can unlock unprecedented value from your data assets.
Qodequay combines design thinking with expertise in AI, Web3, and Mixed Reality to help businesses implement Data Mesh vs. Data Lakehouse: Choosing the Right Architecture effectively. Our methodology ensures user-centric solutions that drive real results and digital transformation.
Ready to implement Data Mesh vs. Data Lakehouse: Choosing the Right Architecture for your business? Contact Qodequay today to learn how our experts can help you succeed. Visit Qodequay.com or schedule a consultation to get started on designing enterprise platforms for your data needs.
As the CEO and Founder of Qodequay Technologies, I bring over 20 years of expertise in design thinking, consulting, and digital transformation. Our mission is to merge cutting-edge technologies like AI, Metaverse, AR/VR/MR, and Blockchain with human-centered design, serving global enterprises across the USA, Europe, India, and Australia. I specialize in creating impactful digital solutions, mentoring emerging designers, and leveraging data science to empower underserved communities in rural India. With a credential in Human-Centered Design and extensive experience in guiding product innovation, I’m dedicated to revolutionizing the digital landscape with visionary solutions.
Follow the expert :
![]()

July 2, 2026

July 2, 2026

July 2, 2026

July 2, 2026

July 2, 2026
Monthly insights on AI, VR and DPDPA compliance — straight from our team to your inbox.
Free 30-minute consultation with our team — or see our products in action.
