DPDPA Penalties Up to ₹250 Crore: The Real Cost of Waiting
July 2, 2026

In today's data-driven world, organizations are grappling with an unprecedented volume, velocity, and variety of information. Extracting meaningful insights from this deluge of data is no longer a luxury but a critical imperative for competitive advantage and operational efficiency. As businesses scale and their data ecosystems grow more complex, traditional monolithic data architectures often struggle to keep pace, leading to data silos, slow data delivery, and a lack of trust in data assets. This challenge has spurred the evolution of new architectural paradigms designed to make data more accessible, reliable, and valuable.
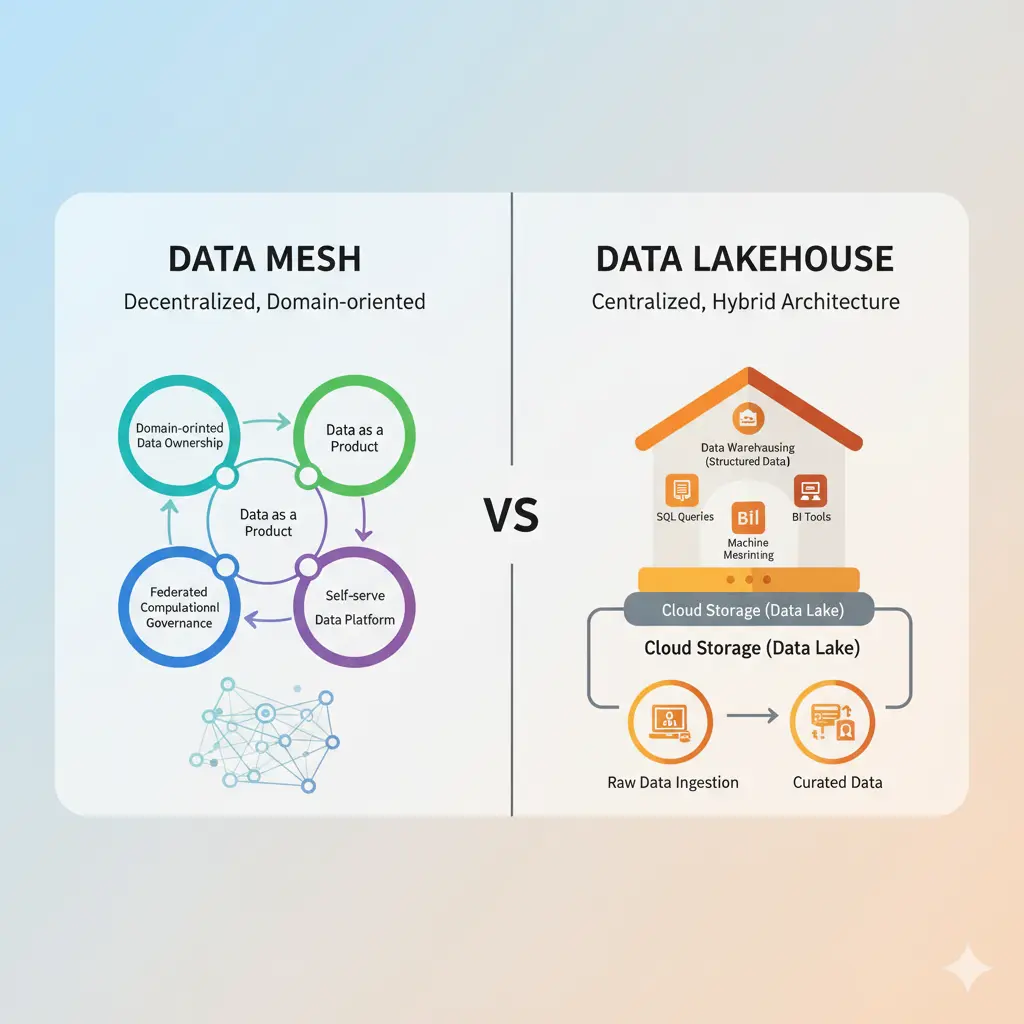
Among the most prominent and impactful of these modern approaches are the Data Mesh and the Data Lakehouse. While both aim to solve the complexities of modern data management and analytics, they do so through fundamentally different philosophies and technical implementations. The Data Mesh proposes a decentralized, domain-oriented approach, treating data as a product owned by the business domains that produce it. In contrast, the Data Lakehouse offers a unified platform that combines the best features of data lakes and data warehouses, providing a single source for both raw data storage and high-performance analytics.
Choosing between these two powerful architectures, or understanding how they might complement each other, is a pivotal decision for any organization embarking on a data modernization journey. This comprehensive guide will delve deep into Data Mesh and Data Lakehouse, explaining their core concepts, key components, and the unique benefits each offers. We will explore why this choice matters significantly in 2024, discuss practical implementation steps, address common challenges with their respective solutions, and outline advanced strategies for optimization and future readiness. By the end of this post, you will have a clear understanding of both architectures and be equipped with the knowledge to make an informed decision that aligns with your specific business needs and strategic objectives, ultimately leading to better data governance, faster insights, reduced complexity, and a future-proof data infrastructure.
The modern data landscape is characterized by an explosion of data, diverse data sources, and an increasing demand for real-time insights. To navigate this complexity, organizations are turning to advanced data architectures like Data Mesh and Data Lakehouse. While both aim to enhance data accessibility, quality, and utility, they approach these goals from distinct perspectives. Understanding these foundational differences is crucial for making an informed architectural decision that aligns with an organization's specific needs and strategic vision.
A Data Mesh is a decentralized, domain-oriented data architecture paradigm that fundamentally shifts how data is managed and consumed within an organization. It's not just a technology stack but a socio-technical approach that emphasizes treating data as a product, owned and served by the business domains that generate it. This paradigm aims to overcome the limitations of centralized data platforms, which often become bottlenecks as organizations scale, by distributing ownership and responsibility for data closer to those who understand it best. For example, in a large retail company, instead of a central data team managing all data, separate domain teams for "customer loyalty," "supply chain logistics," and "online sales" would each own their respective data, ensuring its quality, discoverability, and usability as a product for others.
Conversely, a Data Lakehouse represents a new data architecture that ingeniously combines the best features of data lakes and data warehouses into a single, unified platform. It offers the low-cost, flexible storage and schema-on-read capabilities typically associated with data lakes, alongside the ACID (Atomicity, Consistency, Isolation, Durability) transactions, schema enforcement, and high-performance querying characteristic of data warehouses. This convergence is often achieved through open table formats like Delta Lake, Apache Iceberg, or Apache Hudi, which add transactional capabilities and schema management layers on top of object storage. For instance, an e-commerce platform might use a Data Lakehouse to store vast amounts of raw clickstream data (data lake aspect) while simultaneously performing high-performance SQL queries for real-time business intelligence reports on sales trends and inventory levels (data warehouse aspect), all on the same underlying data.
The distinct philosophies of Data Mesh and Data Lakehouse are reflected in their core components and how they structure data management. Each architecture relies on specific elements to deliver its promised benefits, and understanding these components is vital for appreciating their operational differences.
For a Data Mesh, the key components are primarily organizational and process-driven, supported by technology:
The Data Lakehouse, on the other hand, focuses on technical components that unify storage and processing capabilities:
Each architecture brings distinct advantages to the table, addressing different pain points within an organization's data strategy. The choice often hinges on which set of benefits aligns most closely with the organization's immediate and long-term goals.
The Data Mesh offers several compelling benefits, particularly for large, complex organizations:
The Data Lakehouse, on the other hand, provides a different set of advantages, primarily focused on technical unification and efficiency:
The strategic choice between a Data Mesh and a Data Lakehouse, or a combination thereof, has never been more critical than in 2024. The sheer volume and velocity of data continue to grow exponentially, with organizations generating petabytes of information daily from diverse sources like IoT devices, social media, transactional systems, and customer interactions. This necessitates data architectures that can not only handle immense scale but also provide timely, reliable, and actionable insights to drive business decisions. The demand for real-time analytics, advanced machine learning capabilities, and robust data governance is no longer a competitive differentiator but a core business necessity across almost every industry.
Traditional monolithic data warehouses, while excellent for structured BI, often struggle with the diverse data types, unstructured formats, and the agility required by modern businesses. They can become bottlenecks for data ingestion and transformation, leading to delays in insight generation. Conversely, raw data lakes, while offering flexibility and cost-effective storage, frequently lack the necessary governance, data quality controls, and performance guarantees for critical business intelligence and regulatory compliance, often devolving into "data swamps." Both Data Mesh and Data Lakehouse offer compelling solutions to these persistent challenges, but their philosophical and technical approaches differ significantly. The decision between them, or how to integrate their principles, is crucial for long-term success, impacting everything from operational efficiency and innovation to compliance and competitive advantage in a rapidly evolving digital economy.
The market impact of both Data Mesh and Data Lakehouse architectures is profound and continues to shape the data landscape in 2024. Each paradigm addresses distinct market needs and organizational pain points, leading to their respective widespread adoption and influence.
Data Mesh is gaining significant traction, particularly in large, complex enterprises that are struggling with pervasive data silos, slow data delivery cycles, and a lack of clear data ownership. Its impact is seen in a fundamental shift towards a more distributed and agile data culture. Organizations adopting Data Mesh principles report increased data literacy across business units, faster time-to-insight for specific business domains, and a reduction in the central data team's burden, allowing them to focus on platform development rather than individual data requests. This approach is especially impactful in highly regulated industries or those with diverse product lines, where domain-specific data governance and accountability are paramount. It fosters a sense of ownership that directly translates into higher data quality and trust, which are critical for data-driven decision-making.
The Data Lakehouse has, in many ways, become a de-facto standard for organizations seeking to modernize their data infrastructure without completely overhauling their organizational structure. It offers a pragmatic evolution from separate data lakes and warehouses, providing a unified, cost-effective, and high-performance platform for both analytics and AI workloads. Its market impact is evident in the widespread adoption of technologies like Databricks Delta Lake, Apache Iceberg, Apache Hudi, and the hybrid capabilities offered by cloud data platforms like Snowflake and Google BigQuery. Companies are leveraging Data Lakehouses to consolidate their data, simplify their architecture, and reduce operational overhead, while simultaneously enabling advanced analytics and machine learning on a single, reliable source of truth. This has led to faster model development, more accurate BI reports, and a more efficient use of data engineering resources across the board.
Both Data Mesh and Data Lakehouse are not fleeting trends but foundational shifts that will continue to shape data architecture for the foreseeable future. Their relevance is underpinned by their ability to adapt to evolving technological landscapes and increasing business demands for data.
The Data Mesh will remain highly relevant as organizations continue to scale in size and complexity, and as the imperative for decentralization and agility grows. Its core principles of domain ownership, data as a product, and federated governance are fundamental to building resilient, adaptable, and scalable data ecosystems that can withstand rapid business changes and technological advancements. As data governance becomes increasingly complex with evolving global regulations like GDPR, CCPA, and emerging AI ethics guidelines, the federated governance model of Data Mesh offers a scalable and manageable approach to ensure compliance and responsible data use across distributed teams. It empowers organizations to democratize data access while maintaining control, fostering innovation at the edges of the enterprise.
The Data Lakehouse is also poised to be a foundational layer for future data architectures, constantly evolving to meet new demands. Its ability to handle diverse workloads (batch, streaming, BI, ML), support open data and table formats, and provide transactional reliability makes it highly adaptable to emerging technologies and use cases. Continuous innovation in areas such as query engines, storage optimization, and the capabilities of open table formats (e.g., enhanced indexing, real-time capabilities) will further solidify its position as a versatile and powerful platform. As AI and machine learning become even more pervasive, the Lakehouse's unified approach to data storage and processing will be indispensable for training, deploying, and managing complex models, ensuring that data scientists have access to fresh, high-quality data without needing to move it across disparate systems. The trend towards real-time data processing will also see Lakehouse platforms integrating more deeply with streaming technologies, making them central to operational analytics and immediate decision-making.
Embarking on the journey to implement either a Data Mesh or a Data Lakehouse is a significant undertaking that extends far beyond mere technical configuration. It represents a strategic pivot in how an organization perceives, manages, and leverages its data assets. The initial phase is critical and must involve a thorough understanding of your organization's unique requirements, existing technological landscape, and, crucially, its cultural readiness for change. This is not a one-size-fits-all decision; what works for one enterprise might not be suitable for another. Therefore, before committing to a specific architecture, it is essential to articulate a clear data strategy, identify all key stakeholders from both business and IT, and conduct a comprehensive assessment of your current data infrastructure, including data sources, existing pipelines, and storage solutions. This foundational work of discovery and meticulous planning will establish a robust framework for a successful transition, ensuring that the chosen architecture truly aligns with your overarching business objectives and long-term vision for data-driven growth.
Before diving into the technical implementation of either a Data Mesh or a Data Lakehouse, several foundational elements must be in place to ensure a smooth and successful adoption. These prerequisites address both technical readiness and organizational alignment.
The implementation process for Data Mesh and Data Lakehouse, while sharing common initial steps, diverges significantly in their later stages due to their architectural differences. However, a structured approach is vital for both.
Assess Current State & Define Requirements:
Choose Your Architecture (or Hybrid Approach):
Pilot Project & Proof of Concept (PoC): *
Explore these related topics to deepen your understanding:
As the CEO and Founder of Qodequay Technologies, I bring over 20 years of expertise in design thinking, consulting, and digital transformation. Our mission is to merge cutting-edge technologies like AI, Metaverse, AR/VR/MR, and Blockchain with human-centered design, serving global enterprises across the USA, Europe, India, and Australia. I specialize in creating impactful digital solutions, mentoring emerging designers, and leveraging data science to empower underserved communities in rural India. With a credential in Human-Centered Design and extensive experience in guiding product innovation, I’m dedicated to revolutionizing the digital landscape with visionary solutions.
Follow the expert :
![]()

July 2, 2026

July 2, 2026

July 2, 2026

July 2, 2026

July 2, 2026
Monthly insights on AI, VR and DPDPA compliance — straight from our team to your inbox.
Free 30-minute consultation with our team — or see our products in action.