DPDPA Penalties Up to ₹250 Crore: The Real Cost of Waiting
July 2, 2026
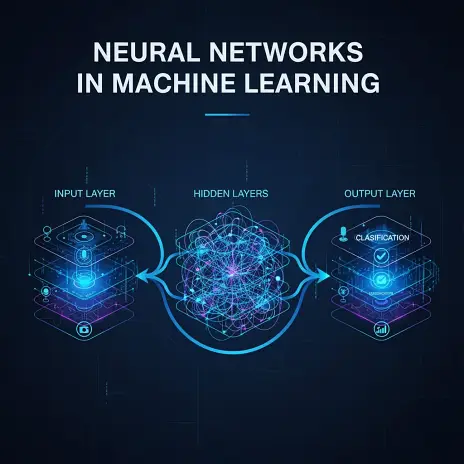
In the rapidly evolving landscape of artificial intelligence, neural networks stand as a foundational pillar, driving much of the innovation we see today. From powering sophisticated recommendation systems and natural language processing tools to enabling groundbreaking advancements in medical diagnostics and autonomous vehicles, these intricate computational models are at the heart of modern machine learning. Understanding neural networks is no longer just for specialized researchers; it is becoming an essential skill for anyone looking to navigate or contribute to the digital future. This comprehensive guide aims to demystify neural networks, breaking down their complex structures and functions into clear, understandable concepts.
Neural networks are inspired by the human brain, designed to recognize patterns and make decisions in a way that mimics biological intelligence. They learn from vast amounts of data, identifying subtle relationships and features that would be impossible for traditional programming methods to uncover. This ability to learn and adapt makes them incredibly powerful for tasks involving perception, prediction, and generation. As businesses and industries increasingly rely on data-driven insights, the demand for professionals who can effectively design, implement, and interpret neural network models continues to grow exponentially. Mastering these concepts opens doors to exciting career opportunities and empowers individuals to build intelligent systems that solve real-world problems.
Throughout this guide, readers will gain a deep understanding of what neural networks are, how they work, and why they are so crucial in 2024. We will explore their core components, delve into practical implementation strategies, discuss common challenges and their solutions, and look ahead at advanced techniques and future trends. By the end, you will not only grasp the theoretical underpinnings but also acquire actionable insights to begin applying neural network principles in your own projects. Whether you are a student, a developer, a data scientist, or a business leader, this guide will equip you with the knowledge needed to leverage the transformative power of neural networks in machine learning.
Neural networks are a subset of machine learning, specifically a type of algorithm that is modeled after the structure and function of the human brain. They are designed to recognize patterns in data, learn from examples, and make predictions or classifications without being explicitly programmed for specific tasks. At their core, neural networks consist of interconnected "neurons" organized in layers, processing information in a feedforward manner, though more complex architectures exist. This architecture allows them to identify intricate relationships and features within large datasets, making them exceptionally powerful for complex problems like image recognition, natural language understanding, and predictive analytics.
The fundamental idea behind a neural network is to simulate how biological neurons transmit signals. Each artificial neuron receives input, processes it, and then passes the result to other neurons. The connections between neurons have "weights" associated with them, which determine the strength and importance of the input. During the training phase, the network adjusts these weights based on the errors it makes, gradually improving its ability to accurately map inputs to desired outputs. This iterative learning process, often involving backpropagation, enables the network to discover highly complex, non-linear patterns that traditional statistical methods might miss, leading to superior performance in many AI applications.
The importance of neural networks stems from their ability to learn from raw data and generalize that learning to new, unseen data. For instance, a neural network trained on thousands of cat images can learn to identify a cat in a new image it has never encountered before, even if the cat is in a different pose, lighting, or background. This capability for automatic feature extraction and hierarchical learning distinguishes them from earlier machine learning models. As data availability and computational power continue to grow, neural networks, particularly deep neural networks with many layers, have become the driving force behind many of the most impressive breakthroughs in artificial intelligence over the last decade.
At the heart of every neural network are several key components that work in concert to process information and learn from data. The most fundamental unit is the neuron (also called a node or perceptron), which receives inputs, performs a simple computation, and then passes the output to subsequent neurons. Each input to a neuron is associated with a weight, a numerical value that determines the strength or importance of that particular input. These weights are the parameters that the network learns during training.
Neurons are organized into layers: an input layer that receives the raw data, one or more hidden layers that perform intermediate computations, and an output layer that produces the final prediction or classification. The number of hidden layers and neurons within them defines the network's depth and capacity to learn complex patterns. Additionally, each neuron typically applies an activation function to its weighted sum of inputs. This non-linear function introduces non-linearity into the model, allowing the network to learn more complex relationships than it could with linear functions alone. Common activation functions include ReLU (Rectified Linear Unit), sigmoid, and tanh. Finally, a bias term is added to the weighted sum of inputs before the activation function, allowing the activation function to be shifted, which provides the network with greater flexibility in modeling.
The primary advantages and value proposition of neural networks are numerous, making them indispensable in modern machine learning. One of their most significant benefits is their ability to learn complex patterns from large and diverse datasets. Unlike traditional algorithms that require explicit feature engineering, neural networks can automatically extract relevant features, even subtle ones, directly from raw data. This capability significantly reduces the manual effort involved in data preparation and allows for the discovery of insights that might otherwise remain hidden. For example, in medical imaging, a neural network can learn to identify cancerous cells from raw pixel data without human intervention to define specific features of cancer.
Another core benefit is their adaptability and generalization capabilities. Once trained, neural networks can generalize their learning to new, unseen data, making accurate predictions or classifications in real-world scenarios. This robustness is crucial for applications where data can vary widely, such as speech recognition or autonomous driving. Furthermore, neural networks excel in handling various data types, including images, text, audio, and numerical data, often achieving state-of-the-art performance across these domains. Their inherent parallel processing nature also allows for efficient computation on specialized hardware like GPUs, accelerating the training and inference processes. Finally, the continuous advancements in neural network architectures and training techniques mean they are constantly improving, pushing the boundaries of what artificial intelligence can achieve.
In 2024, understanding neural networks is more critical than ever due to their pervasive influence across virtually every industry and their role as the backbone of cutting-edge AI advancements. The rapid proliferation of data, coupled with increasing computational power, has propelled neural networks from academic curiosities to indispensable tools for solving real-world problems. From enhancing customer experiences through personalized recommendations and intelligent chatbots to revolutionizing scientific research and industrial automation, neural networks are driving innovation and competitive advantage. Businesses that grasp the principles and applications of neural networks are better positioned to leverage AI for strategic decision-making, operational efficiency, and the development of new products and services.
The relevance of neural networks in 2024 is also underscored by the ongoing democratization of AI tools and platforms. Frameworks like TensorFlow and PyTorch have made it easier for developers and data scientists to build and deploy sophisticated neural network models without needing to write complex algorithms from scratch. This accessibility means that even smaller organizations can now harness the power of deep learning, creating a competitive landscape where AI literacy is paramount. Furthermore, as AI systems become more integrated into daily life, a fundamental understanding of how neural networks learn and operate is crucial for addressing ethical considerations, ensuring fairness, and building transparent and trustworthy AI. This knowledge empowers individuals to critically evaluate AI applications and contribute responsibly to their development.
The current market trends clearly indicate a sustained and growing demand for expertise in neural networks. Industries such as healthcare, finance, automotive, retail, and entertainment are heavily investing in AI capabilities powered by neural networks. For instance, in healthcare, neural networks are used for drug discovery, disease diagnosis, and personalized treatment plans. In finance, they power fraud detection, algorithmic trading, and credit scoring. The business impact is profound: companies are achieving unprecedented levels of automation, predictive accuracy, and insight generation, leading to significant cost savings, revenue growth, and enhanced customer satisfaction. Those who understand neural networks are not just observers of this transformation but active participants and architects of the future.
The market impact of neural networks in 2024 is transformative and far-reaching, fundamentally reshaping how businesses operate and compete. Companies that effectively deploy neural network solutions are gaining significant competitive advantages, driving innovation, and unlocking new revenue streams. For example, in e-commerce, neural networks power recommendation engines that personalize shopping experiences, leading to increased sales and customer loyalty. In manufacturing, they enable predictive maintenance, reducing downtime and optimizing production processes. The ability of neural networks to process vast amounts of data and identify actionable insights allows businesses to make more informed decisions, respond faster to market changes, and anticipate customer needs with greater precision.
Moreover, the rise of neural networks has spurred the growth of an entirely new ecosystem of AI-driven products and services. This includes specialized hardware like AI accelerators (GPUs, TPUs), cloud-based AI platforms, and a burgeoning market for AI consulting and development services. The demand for skilled professionals proficient in neural network design, training, and deployment has skyrocketed, creating a vibrant job market and driving educational initiatives. The market is also witnessing a shift towards AI-first strategies, where companies are re-imagining their core operations and offerings around AI capabilities, with neural networks often at the core of these transformations. This pervasive impact ensures that understanding neural networks is not just beneficial but essential for staying relevant in today's technology-driven economy.
Neural networks will undoubtedly remain critically important in the future, serving as the cornerstone for continued advancements in artificial intelligence. Their fundamental ability to learn from data and generalize patterns positions them as the primary engine for tackling increasingly complex problems. As data generation continues its exponential growth, and computational power becomes even more accessible, neural networks will only become more sophisticated and capable. We can expect to see them integrated into more aspects of daily life, from highly personalized digital assistants that understand nuanced human emotions to fully autonomous systems that operate with minimal human intervention.
Looking ahead, research into neural networks is constantly pushing boundaries, exploring new architectures like Transformers for advanced natural language processing, Graph Neural Networks for relational data, and Spiking Neural Networks for energy-efficient, brain-inspired computing. These innovations promise to unlock even greater potential, enabling AI to solve problems that are currently intractable. Furthermore, as AI systems become more powerful, there will be an increased focus on areas like explainable AI (XAI), ethical AI, and robust AI, all of which will require a deep understanding of neural network mechanics to ensure responsible development and deployment. Therefore, a solid grasp of neural networks today provides a strong foundation for understanding and contributing to the AI innovations of tomorrow.
Getting started with neural networks involves a structured approach, beginning with foundational knowledge and progressing to practical application. The journey typically starts with understanding the basic mathematical concepts behind neurons, weights, biases, and activation functions. Familiarity with linear algebra, calculus (especially derivatives for optimization), and probability is highly beneficial, though modern libraries abstract much of this complexity. The next crucial step is to choose a programming language, with Python being the dominant choice due to its extensive ecosystem of AI libraries. Learning to use popular frameworks like TensorFlow or PyTorch is essential, as they provide high-level APIs to build, train, and deploy neural networks efficiently.
Once the theoretical and tool-based foundations are laid, practical implementation begins with data. Neural networks are data-hungry, so acquiring, cleaning, and preprocessing data is a critical initial phase. This involves tasks like normalization, standardization, and splitting data into training, validation, and test sets. Next, you define the architecture of your neural network, specifying the number of layers, neurons per layer, and activation functions. For example, a simple feedforward neural network for classifying handwritten digits might have an input layer matching the image pixel count, a few hidden layers with ReLU activations, and an output layer with 10 neurons (for digits 0-9) using a softmax activation. The model is then compiled with an optimizer (e.g., Adam, SGD) and a loss function (e.g., categorical cross-entropy for classification).
The final steps involve training the network using your prepared data, monitoring its performance on the validation set, and iteratively adjusting hyperparameters (like learning rate, batch size, and number of epochs) to optimize results. After satisfactory performance is achieved, the model is evaluated on the unseen test set to assess its generalization ability. This iterative process of experimentation, training, and evaluation is central to successful neural network implementation. Starting with simple datasets and models, such as the MNIST handwritten digit classification or Iris flower classification, provides excellent hands-on experience before tackling more complex problems.
Before diving into the practical implementation of neural networks, several prerequisites are highly recommended to ensure a smooth and effective learning experience. Firstly, a solid grasp of programming fundamentals, particularly in Python, is essential. This includes understanding data structures, control flow, functions, and object-oriented programming concepts. Python's simplicity and rich ecosystem of libraries make it the de facto standard for machine learning.
Secondly, a basic understanding of mathematics is crucial. This doesn't mean you need to be a math genius, but familiarity with concepts from linear algebra (vectors, matrices, dot products), calculus (derivatives, gradients), and probability/statistics (mean, variance, distributions) will greatly aid in comprehending how neural networks learn and optimize. For instance, understanding matrix multiplication is key to grasping how data flows through layers, and derivatives are fundamental to the backpropagation algorithm. Finally, familiarity with data science concepts such as data preprocessing, feature engineering (even if neural networks automate some of it), and model evaluation metrics (accuracy, precision, recall, F1-score) will provide a robust framework for building and assessing your neural network models.
Implementing a neural network typically follows a well-defined sequence of steps:
Data Collection and Preparation: This is often the most time-consuming step. Gather relevant data, clean it by handling missing values and outliers, and preprocess it. Preprocessing includes tasks like scaling numerical features (e.g., normalization or standardization), encoding categorical variables (e.g., one-hot encoding), and splitting the dataset into training, validation, and test sets. For example, if working with images, this might involve resizing, cropping, and normalizing pixel values.
Model Architecture Definition: Design the structure of your neural network. This involves deciding on the type of network (e.g., feedforward, convolutional, recurrent), the number of layers (input, hidden, output), the number of neurons in each layer, and the activation function for each layer. For a simple classification task, you might start with a few dense layers.
Model Compilation: Configure the learning process. This involves choosing an optimizer (e.g., Adam, SGD, RMSprop) that will adjust the network's weights during training, a loss function (e.g., mean squared error for regression, categorical cross-entropy for multi-class classification) that quantifies the error between predicted and actual outputs, and metrics (e.g., accuracy, F1-score) to monitor performance.
Model Training: Feed the preprocessed training data to the network. The network iterates through the data multiple times (epochs), adjusting its weights based on the calculated loss and the optimizer's strategy. During training, it's crucial to monitor performance on the validation set to detect overfitting. This is where the network "learns" the patterns in the data.
Model Evaluation: After training, assess the model's performance on the unseen test set. This provides an unbiased estimate of how well the model will generalize to new data. Metrics like accuracy, precision, recall, and F1-score are used to quantify performance. Visualizations like confusion matrices can also offer deeper insights.
Hyperparameter Tuning and Iteration: Based on evaluation results, you might need to adjust hyperparameters (e.g., learning rate, batch size, number of epochs, network architecture) and repeat the training and evaluation steps. This iterative process is crucial for optimizing model performance.
Deployment (Optional): Once the model performs satisfactorily, it can be deployed into a production environment to make real-time predictions or classifications. This might involve integrating it into a web application, mobile app, or backend service.
Adhering to best practices is crucial for effectively understanding, building, and deploying neural networks that are robust, efficient, and performant. One fundamental best practice is to start simple and iterate. Instead of immediately jumping to complex architectures, begin with a basic model and gradually add complexity as needed. This approach helps in debugging, understanding the impact of each change, and avoiding unnecessary computational overhead. For example, when tackling a new image classification problem, start with a small convolutional neural network (CNN) before attempting a deep ResNet or Transformer architecture. This iterative refinement allows for systematic improvement and a clearer understanding of what works best for your specific problem and data.
Another critical best practice involves rigorous data management and preprocessing. Neural networks are highly sensitive to the quality and representation of input data. Ensuring data cleanliness, handling missing values appropriately, and applying consistent scaling or normalization techniques across all datasets (training, validation, test) are paramount. For instance, normalizing image pixel values to a range of 0-1 or standardizing numerical features to have zero mean and unit variance can significantly improve training stability and model performance. Furthermore, using a dedicated validation set during training is essential to monitor for overfitting and guide hyperparameter tuning, preventing the model from simply memorizing the training data rather than learning generalizable patterns. Without a proper validation set, it's easy to build a model that performs well on training data but poorly on new, unseen data.
Finally, effective hyperparameter tuning and regularization are key to optimizing neural network performance. Hyperparameters, such as learning rate, batch size, number of epochs, and network architecture, cannot be learned by the model itself and must be set by the developer. Techniques like grid search, random search, or more advanced methods like Bayesian optimization can help find optimal combinations. Simultaneously, employing regularization techniques like dropout (randomly dropping neurons during training) or L1/L2 regularization (adding penalties to weights) helps prevent overfitting, especially in deep networks with many parameters. These practices ensure that the model not only learns effectively but also generalizes well to new data, making it reliable for real-world applications.
In the field of neural networks, several industry standards have emerged to ensure consistency, reproducibility, and efficiency in development and deployment. Using established frameworks like TensorFlow, PyTorch, and Keras is a universal standard. These frameworks provide robust, optimized, and well-documented tools for building, training, and deploying models, abstracting away much of the low-level complexity. They also foster a large community, making it easier to find resources and support. Another standard is the adoption of cloud computing platforms (AWS, Google Cloud, Azure) for training large-scale neural networks. These platforms offer scalable computational resources (GPUs, TPUs) and managed services that significantly accelerate development cycles and reduce infrastructure overhead.
Furthermore, version control systems like Git are standard practice for managing code, model configurations, and even trained model weights, facilitating collaboration and tracking changes. Reproducibility is also a key standard, meaning that experiments should be designed and documented in a way that allows others (or yourself in the future) to replicate the results. This includes specifying random seeds, exact library versions, and detailed preprocessing steps. Finally, adherence to MLOps (Machine Learning Operations) principles is becoming an industry standard for deploying and managing machine learning models in production. This involves automating the entire lifecycle, from data ingestion and model training to deployment, monitoring, and continuous retraining, ensuring models remain effective and reliable over time.
Industry experts consistently emphasize several key recommendations for those working with neural networks. Firstly, focus on data quality and quantity. As Andrew Ng famously stated, "data is the new oil." High-quality, well-labeled data is often more impactful than complex model architectures. Experts recommend spending significant time on data collection, cleaning, augmentation, and understanding its characteristics. Secondly, leverage transfer learning whenever possible. Instead of training models from scratch, which is computationally expensive and data-intensive, fine-tuning pre-trained models (e.g., VGG, ResNet, BERT) on your specific dataset can yield superior results with less data and computational resources. This is particularly effective in computer vision and natural language processing.
Thirdly, understand the limitations and biases of your models. Neural networks are powerful but not infallible. Experts advise rigorous testing for fairness, robustness, and interpretability. Understanding why a model makes certain predictions, especially in critical applications like healthcare or finance, is paramount. Techniques like LIME or SHAP can help in this regard. Fourthly, stay updated with research and community developments. The field of neural networks is rapidly evolving, with new architectures, optimization techniques, and best practices emerging constantly. Engaging with research papers, online courses, and communities like Kaggle or arXiv is crucial for continuous learning. Finally, experimentation is key. Neural network development is often an empirical science. Experts recommend maintaining a systematic approach to experimentation, tracking results, and learning from both successes and failures to continually improve model performance.
Despite their power, working with neural networks presents several common challenges that can hinder development and deployment. One of the most frequent issues is overfitting, where a model learns the training data too well, including its noise and specific patterns, but fails to generalize to new, unseen data. This often occurs when the model is too complex for the amount of training data available or when training is continued for too long. An overfit model will show excellent performance on the training set but poor performance on the validation and test sets, making it unreliable for real-world applications.
Another significant challenge is the computational intensity and resource requirements of training deep neural networks. Training large models, especially those with many layers and parameters, can require substantial computational power (GPUs, TPUs) and significant time, sometimes days or even weeks. This can be a barrier for individuals or organizations with limited resources. Furthermore, data scarcity or poor data quality poses a major hurdle. Neural networks are data-hungry, and insufficient or noisy data can lead to poor model performance, regardless of the network architecture. Obtaining large, clean, and well-labeled datasets is often a laborious and expensive process.
Finally, the "black box" nature of deep neural networks can be a problem. While they achieve high accuracy, it can be difficult to understand why a neural network makes a particular prediction. This lack of interpretability is a concern in applications where transparency and accountability are critical, such as medical diagnosis, financial lending, or legal decisions. Debugging and improving such models can also be challenging without a clear understanding of their internal decision-making processes.
The top 3-5 problems people frequently encounter when working with neural networks include:
These problems typically occur due to several underlying factors inherent in neural network design and training:
Addressing the common challenges in neural network development requires a combination of quick fixes for immediate issues and long-term strategies for robust model building. For problems like overfitting, quick fixes include early stopping, where training is halted once performance on the validation set starts to degrade, preventing the model from memorizing the training data. Another immediate solution is to reduce the model's complexity by decreasing the number of layers or neurons, making it less prone to learning noise. For vanishing/exploding gradients, using gradient clipping (limiting gradient values) or switching to activation functions like ReLU (which don't suffer from vanishing gradients in the same way as sigmoid/tanh) can provide quick relief.
For data-related issues, if data scarcity is a problem, data augmentation can be a quick way to artificially increase the size of your training dataset by creating modified versions of existing data (e.g., rotating, flipping, or zooming images; paraphrasing text). If data quality is poor, a rapid solution might involve simple filtering rules to remove obvious outliers or incorrect labels, though this requires careful manual inspection. For computational resource constraints, utilizing pre-trained models through transfer learning is an excellent quick fix, as it significantly reduces the need for extensive training from scratch, requiring less data and computational power. These immediate solutions can often get a model to a functional state quickly, allowing for further refinement.
Here are some immediate solutions for urgent problems:
For comprehensive approaches to prevent recurring issues and build robust neural networks:
Moving beyond foundational concepts, expert-level understanding of neural networks involves delving into advanced methodologies and sophisticated optimization strategies that push the boundaries of AI capabilities. One such area is architectural innovation, where experts design novel network structures tailored for specific problems. This includes understanding and implementing advanced architectures like Transformer networks for sequence-to-sequence tasks (e.g., machine translation, large language models like GPT), Graph Neural Networks (GNNs) for data with complex relational structures (e.g., social networks, molecular structures), and Generative Adversarial Networks (GANs) for generating realistic data (e.g., images, audio). These architectures move beyond simple feedforward or recurrent connections, introducing mechanisms like attention, message passing, or adversarial training to achieve superior performance on highly complex tasks.
Another expert-level technique is meta-learning, or "learning to learn." This involves designing models that can quickly adapt to new tasks or datasets with minimal training data. For example, few-shot learning, a subfield of meta-learning, enables models to learn new concepts from just a handful of examples, mimicking human learning capabilities. Techniques like MAML (Model-Agnostic Meta-Learning) allow a model to learn an initialization that can be quickly fine-tuned for a new task. Furthermore, experts often employ ensemble methods where multiple neural networks, sometimes with different architectures or trained on different subsets of data, are combined to make predictions. This approach often leads to more robust and accurate results than any single model alone, by averaging out individual model biases and errors.
Finally, a deep understanding of unsupervised and self-supervised learning is crucial for expert-level application. While supervised learning relies on labeled data, unsupervised methods like autoencoders learn representations from unlabeled data, which is abundant. Self-supervised learning, a more recent paradigm, creates supervisory signals from the data itself (e.g., predicting missing parts of an image or predicting the next word in a sentence). These techniques are vital for leveraging vast amounts of unlabeled data, reducing the reliance on expensive manual annotation, and learning powerful, generalizable representations that can then be used for downstream supervised tasks with much less labeled data.
Sophisticated approaches and techniques in neural networks often involve specialized architectures and learning paradigms.
Maximizing efficiency and results in neural networks goes beyond basic gradient descent and involves advanced optimization techniques.
The future of neural networks in machine learning is poised for continuous innovation, driven by emerging trends and a relentless pursuit of more intelligent, efficient, and ethical AI systems. One of the most significant emerging trends is the development of increasingly larger and more capable foundation models, exemplified by large language models (LLMs) like GPT-4 and large vision models. These models, pre-trained on vast amounts of diverse data, can perform a wide range of tasks with remarkable few-shot or zero-shot capabilities, acting as versatile backbones for various applications. The focus will shift from training specific models for specific tasks to fine-tuning these powerful general-purpose models for specialized needs, democratizing advanced AI.
Another key trend is the growing emphasis on efficiency and sustainability. As models grow larger, their computational and energy footprints become substantial. Future research will focus on developing more energy-efficient architectures, model compression techniques (like pruning and quantization for deployment on edge devices), and hardware-aware neural network design. This push for efficiency will enable AI to be deployed in more constrained environments, from IoT devices to remote sensors, expanding its reach and impact. Furthermore, the field will see continued advancements in multimodal AI, where neural networks can seamlessly integrate and process information from various modalities like text, images, audio, and video, leading to more holistic and human-like understanding.
The future will also bring a stronger focus on responsible AI development. As neural networks become more powerful and ubiquitous, addressing concerns around bias, fairness, interpretability, and privacy will become paramount. Research into Explainable AI (XAI) will continue to mature, providing tools and methodologies to understand the decision-making processes of complex models. Techniques for privacy-preserving AI, such as federated learning and differential privacy, will become standard practice, allowing models to learn from decentralized data without compromising individual privacy. Ultimately, the future of neural networks is not just about building more intelligent systems, but about building intelligent systems that are also trustworthy, equitable, and beneficial for all of humanity.
The landscape of neural networks is constantly evolving, with several key trends shaping its future:
To stay ahead in the rapidly evolving field of neural networks, individuals and organizations must adopt proactive strategies:
Explore these related topics to deepen your understanding:
Understanding neural networks is no longer an academic pursuit but a practical necessity in our increasingly AI-driven world. We have explored their fundamental components, from individual neurons and layers to activation functions and weights, highlighting how these elements combine to enable sophisticated pattern recognition and decision-making. We delved into the profound reasons why neural networks matter in 2024, examining their transformative market impact and enduring future relevance across diverse industries. From personalized recommendations to advanced medical diagnostics, their influence is undeniable and continues to expand.
Moreover, this guide provided a comprehensive roadmap for implementing neural networks, outlining essential prerequisites, a step-by-step process for building and training models, and crucial best practices for ensuring robustness and efficiency. We addressed common challenges such as overfitting, vanishing gradients, and data scarcity, offering both quick fixes and long-term solutions to overcome these hurdles. Finally, we ventured into advanced strategies, discussing expert-level techniques like Transformer networks and GANs, alongside optimization methods and a forward-looking perspective on emerging trends like foundation models and ethical AI. The journey into neural networks is one of continuous learning and experimentation. The insights and practical advice shared here are designed to equip you with a solid foundation, enabling you to confidently navigate this complex yet incredibly rewarding field. The power to build intelligent systems that can learn, adapt, and solve real-world problems is within reach. Embrace the challenge, apply these principles, and contribute to shaping the future of Ai Workflow Automation Tools.
Qodequay combines design thinking with expertise in AI, Web3, and Mixed Reality to help businesses implement Understanding Neural Networks in Machine Learning effectively. Our methodology ensures user-centric solutions that drive real results and digital transformation, potentially leading to Ambient Invisible Intelligence.
Ready to implement Understanding Neural Networks in Machine Learning for your business? Contact Qodequay today to learn how our experts can help you succeed. Visit Qodequay.com or schedule a consultation to get started with Ai For Circular Economy Designing Products With Lifecycle Intelligence.
As the CEO and Founder of Qodequay Technologies, I bring over 20 years of expertise in design thinking, consulting, and digital transformation. Our mission is to merge cutting-edge technologies like AI, Metaverse, AR/VR/MR, and Blockchain with human-centered design, serving global enterprises across the USA, Europe, India, and Australia. I specialize in creating impactful digital solutions, mentoring emerging designers, and leveraging data science to empower underserved communities in rural India. With a credential in Human-Centered Design and extensive experience in guiding product innovation, I’m dedicated to revolutionizing the digital landscape with visionary solutions.
Follow the expert :
![]()

July 2, 2026

July 2, 2026

July 2, 2026

July 2, 2026

July 2, 2026
Monthly insights on AI, VR and DPDPA compliance — straight from our team to your inbox.
Free 30-minute consultation with our team — or see our products in action.
